

Hi! Before we start, a word of caution: This is an extremely long article, and it might take multiple hours to finish completely. But I promise it'll be worth it.
Oh, and follow me on twitter, I frequently post Python content there as well.
Index
- So what is an AST?
- Python's
astmodule - Walking the Syntax Trees with Visitors
- The power of AST manipulation
- Let's build: A simple linter
- AST utilities
- What about code formatters?
- Where can I learn more?
So what is an AST?
It's short for Abstract Syntax Tree. In programmer terms, "ASTs are a programmatic way to understand the structure of your source code". But to understand what that really means, we must first understand a few things about the structure of a computer program.
The programs that you and I write in our language of choice is usually called the "source code", and I'll be referring to it as such in this article.
On the other end, computer chips can only understand "machine code", which is a set of binary numbers that have special meanings for that model of the chip. Some of these numbers are instructions, which tell the CPU a simple task to perform, like "add the numbers stored in these two places", or "jump 10 numbers down and continue running code from there". The instructions run one by one, and they dictate the flow of the program.
Similarly, you define your programs as a set of "statements", with each statement being one thing that you want your code to do. They're sort of a more human-friendly version of the CPU instructions, that we can write and reason with more easily.
Now, I know that theory can get boring really quick, so I'm going to go through a bunch of examples. Let's write the same piece of code in many languages, and notice the similarities:
-
Python
def area_of_circle(radius): pi = 3.14 return pi * radius * radius area_of_circle(5) # Output: 78.5 -
Scheme Lisp
(define (area_of_circle radius) (define pi 3.14) (* pi radius radius)) (area_of_circle 5) ; Output: 78.5 -
Go
package main func area_of_circle(radius float64) float64 { pi := 3.14 return pi * radius * radius } func main() { println(area_of_circle(5)) } // Output: +7.850000e+001
We're doing essentially the same thing in all of these, and I'll break it down piece by piece:
-
We're defining our source code as a block of statements. In our case, there are two statements at the top-level of our source code: one statement that defines our
area_of_circlefunction, and another statement that runs this function with the value "5". -
The definition of the
area_of_circlefunction has two parts: the input parameters (the radius, in our case), and the body, which itself is a block of statements. There's two statements insidearea_of_circleto be specific: the first one definespi, and the second one uses it to calculate the area, and returns it. -
For the languages that have a main function, the definition of the main function itself is a statement. Inside that statement we are writing more statements, like one that prints out the value of
area_of_circlecalled with the radius of 5.
You can start to see the somewhat repetitive nature of source code. There's blocks of statements, and sometimes within those statements there can be more statements, and so on. If you imagine each statement to be a "node", then you can think of each of these nodes being composed of one or more other "nodes". You can properly define this kind of structure as a "tree":
(program)
/ \
(area_of_circle r) (main)
/ | |
define calculate run area_of_circle
pi area with r = 5
/ |
multiply (pi, r, r)The nodes here can be anything, from statements, to expressions, to any other construct that the language defines. Once the code is in this tree structure, computers can start to make sense of it, such as traversing its nodes one by one and generate the appropriate machine code.
Essentially, all your code represents a tree of data. And that tree is called the Abstract Syntax Tree. Each programming language has its own AST representation, but the idea is always the same.
To be able to create tools that do things like auto-format your code, or find subtle bugs automatically, you need ASTs to be able to meaningfully read through the code, find items or patterns inside the code, and act on them.
Python's ast module
Python has a builtin ast module, which has a rich set of features to create, modify and run ASTs from Python code. Not all languages provide easy access to their syntax trees, so Python is already pretty good in that regard. Let's take a look at what all the ast module gives us, and try to do something interesting with it:
All the Nodes
There are lots of kinds of "Nodes" in a Python AST each with their own functionalities, but you can broadly divide them into four categories: Literals, Variables, Statements and Expressions. We'll take a look at them one by one, but before we do that we need to understand how a "Node" is represented.
The role of a node is to concretely represent the features of a language.
It does so by:
- Storing the attributes specific to itself, (for example, an
Ifnode that represents an if-statement might need aconditionattribute, which is an expression that evaluates totrueorfalse. The if statement's body will only run whenconditionends up beingtrue. - Defining what children the node can have. (In our
Ifnode's case, it should have abody, that is a list of statements.)
In Python's case, the AST nodes also hold their exact location in the source code. You can find out from where in the Python file a node came from, by checking the
linenoandcol_offsetparameters.
Let's see the concrete example of this if statement, in Python's AST representation.
For this source code:
if answer == 42:
print('Correct answer!')The AST looks like this:
Module(
body=[
If(
test=Compare(
left=Name(id='answer', ctx=Load()),
ops=[Eq()],
comparators=[Constant(value=42)]
),
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[Constant(value='Correct answer!')],
keywords=[]
)
)
],
orelse=[]
)
],
type_ignores=[]
)Let's break this down:
Ignoring the details for now, the overall structure of the AST looks like this:
Module(
body=[
If(
test=Compare(...),
body=[
...
],
)
],
)At the top level, is a Module. All Python files are compiled as "modules" when making the AST. Modules have a very specific meaning: anything that can be run by Python classifies as a module. So by definition, our Python file is a module.
It has a body, which is a list. Specifically, a list of statements. All Python files are just that: a list of statements. Every Python program that you've ever written, read or run -- just that.
In our case, we have just one statement in the module's body: an If-statement. The if-statement has two components: a test, and a body. The test part holds the condition expression, and the body holds the block of statements that's inside the if.
Let's look at the test "expression" first:
If(
test=Compare(
left=Name(id='answer', ctx=Load()),
ops=[Eq()],
comparators=[Constant(value=42)]
),
...In our case, we have a Compare expression -- which makes sense. Python defines comparisons quite thoroughly in its reference, and if you read it, you'll find that Python supports comparison chaining.
From the docs:
Python's comparison expressions support this syntax:
a op1 b op2 c ...Which is equivalent to:
a op1 b and b op2 c and ...
In human terms, this means that Python can support stuff like this:
x = get_number()
if 0 < x < 10:
print('Your number is a single digit!')And 0 < x < 10 is the same as asking 0 < x and x < 10.
Here's the important part: for Python to support this, the AST needs to support this. And Python's AST supports comparison chaining by storing the operators and the comparators (variables) inside lists. You can look at it in the REPL itself:
>>> import ast
>>> def get_ast(code):
... print(ast.dump(ast.parse(code), indent=2))
...
>>> get_ast('a < b > c > d')
Module(
body=[
Expr(
value=Compare(
left=Name(id='a', ctx=Load()),
ops=[Lt(), Gt(), Gt()],
comparators=[
Name(id='b', ctx=Load()),
Name(id='c', ctx=Load()),
Name(id='d', ctx=Load())
]
)
)
],
type_ignores=[]
)If you actually run this code, you might notice that the output here has different whitespace compared to what I have in my blog. It's just personal preference, if you find an output similar to mine more readable you can install
astprettyfrom pip, and use:def get_ast(code): astpretty.pprint(ast.parse(code), show_offsets=False, indent=2)
You can see that the operators <, > and > are stored as ops=[Lt(), Gt(), Gt()] inside the Compare object. The four values are stored a bit more peculiarly: The variable a is stored in a separate field called left, and then every other variable is stored in a list called comparators:
comparators=[
Name(id='b', ctx=Load()),
Name(id='c', ctx=Load()),
Name(id='d', ctx=Load()),
],
...In other words: the leftmost variable is stored in left, and every variable on the right of each operator is stored in the respective index of comparators.
Hopefully that clarifies what the test expression means in our example code:
If(
test=Compare(
left=Name(id='answer', ctx=Load()),
ops=[Eq()],
comparators=[Constant(value=42)]
),
...left is the Name node 'answer' (basically, a variable), and we have just one comparison going on: Eq being applied on the constant value 42. Essentially it is the answer == 42 part of the code.
Now let's look at the body:
If(
test=...,
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[Constant(value='Correct answer!')],
keywords=[]
)
)
],
orelse=[]
)The body in our case is a single Expression. Note that, when I said that a block or module always contains a list of statements, I wasn't lying. This Expr right here is actually an expression-statement. Yeah, I'm not making this up, it will make sense in a bit.
Expressions vs. Statements
Statements are pretty easy to define. They're kind of like the building blocks of your code. Each statement does something that you can properly define. Such as:
-
Creating a variable
x = 5This one becomes an
Assignstatement:Assign( targets=[ Name(id='x', ctx=Store()) ], value=Constant(value=5) )Pretty straightforward, the node stores a target and a value.
targetshere is a list because you can also do multiple assignments:a = b = 5. There will only be one value, though. -
Importing a module
import randomThis one becomes an
Importstatement:Import( names=[ alias(name='random') ] ) -
Asserting some property
assert FalseBecomes:
Assert( test=Constant(value=False) ) -
Doing absolutely nothing
passBecomes:
Pass()
On the other hand, an expression is basically anything that evaluates to a value. Any piece of syntax that ends up turning into a "value", such as a number, a string, an object, even a class or function. As long as it returns a value to us, it is an expression.
This includes:
-
Identity checks
This refers to the
isexpression:>>> a = 5 >>> b = a >>> b 5 >>> a is b TrueClearly,
a is breturns eitherTrueorFalse, just like any other conditional check. And since it returns a value, it is an expression.Here's its AST:
Compare( left=Name(id='a', ctx=Load()), ops=[Is()], comparators=[ Name(id='b', ctx=Load()) ] )And it really is just like conditionals. Turns out
isis treated just as a special operator (like<,==and so on) inside aCompareobject when talking about ASTs. -
Function calls
Function calls return a value. That makes them the most obvious example of an expression:
>>> from os import getpid >>> getpid() 15206Here's what the AST for
getpid()looks like, it'se essrntially just aCall:Call( func=Name(id='getpid', ctx=Load()), args=[], keywords=[] )print('Hello')would look like this, it has one argument:Call( func=Name(id='print', ctx=Load()), args=[Constant(value='hello')], keywords=[] ) -
Lambdas
Lambdas themselves are expressions. When you create a lambda function, you usually pass it directly as an argument to another function, or assign it to a variable. Here's some examples:
>>> lambda: 5 <function <lambda> at 0x7f684169cb80> >>> returns_five = lambda: 5 >>> returns_five() 5 >>> is_even = lambda num: num % 2 == 0 >>> list(filter(is_even, [1, 2, 3, 4, 5])) [2, 4] >>> list(filter(lambda num: num % 2, [1, 2, 3, 4, 5])) [1, 3, 5]And there's the
Lambdaexpression forlambda: 5in the AST:Lambda( args=arguments( posonlyargs=[], args=[], kwonlyargs=[], kw_defaults=[], defaults=[] ), body=Constant(value=5) )
Now, if you think about it, a call to print() in a regular code, it's technically a statement, right?
def greet():
print('Hello world!')As I've said before, blocks of code are essentially just a list of statements. And we also know, that calling print is technically an expression (it even returns None!). So what's going on here?
The answer is simple: Python lets you treat any expression as a standalone statement. The expression is going to return some value, but that value just gets discarded.
Getting back to our original AST:
If(
test=...,
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[Constant(value='Correct answer!')],
keywords=[]
)
)
],
orelse=[]
)We have an Expr in our body, which is Python's way of saying "This is an expression that's being used as a statement". The actual expression is inside it, a Call to print.
The last thing left in this example AST is the last line: orelse=[]. orelse refers to else: blocks anywhere in the AST. The name orelse was chosen because else itself is a keyword and can't be used as an attribute name.
Oh, did you know that for loops in Python can have an else clause?
Extras: The for-else clause
for-else is really interesting. The else in for loops is run whenever the loop runs to its entirety. In other words, it is not run, when you break out of the loop before it finishes.
It's useful for many use-cases, one of them being searching through a list:
items = ['Bag', 'Purse', 'Phone', 'Wallet']
for item in items:
if item == 'Phone':
print('Phone was found in items!')
break
else:
print('Phone was not found in items :(')If we had an else-clause on our for loop, like:
for item in items:
print(item)
else:
print('All done')The AST would look more interesting:
For(
target=Name(id='item', ctx=Store()),
iter=Name(id='items', ctx=Load()),
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='item', ctx=Load())],
keywords=[]
)
)
],
orelse=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Constant(value='All done')
],
keywords=[]
)
)
]
)Pretty straightforward. Also, If statements have the exact same orelse property as for loops when it comes to ASTs.
If you want a detailed reference of all the Nodes that we have in a Python AST, and the corresponding syntax it belongs to, you can either head on to the docs here, or just use ast.dump on a line of code to try and find out for yourself.
What's a ctx?
Ideally, I want you to leave this article understanding every single aspect of Python's ASTs. And if you're one of the few super observant readers, you might have noticed that we glanced over a very small thing in the AST examples shown. You can see it in this code snippet:
Compare(
left=Name(id='a', ctx=Load()),
ops=[Eq()],
comparators=[
Name(id='b', ctx=Load())
]
)We've talked about Compare, we've talked about what the left, ops and comparators fields represent, we've also talked about Name nodes. The only thing left is ctx=Load(). What exactly does that mean?
If you check all the code snippets we've seen so far, we've actually seen 27 instances of Name nodes in the examples. Out of the 27, 25 have had the property ctx=Load(), but two of them have a different value: ctx=Store(). Like this one:
Assign(
targets=[
Name(id='x', ctx=Store())
],
value=Constant(value=5)
)ctx (short for "context") is an essential concept of Python (and many other programming languages), and it is related to the whole concept of "variables".
If I were to ask you "what's a variable?" You might say something like "It can store values which you can use later.", and give some example like:
age = 21 # Here `age` is being used to store data
print(age) # The stored data is being taken out hereAnd that's exactly what it is. If you look at the AST for this code:
>>> def get_ast(code):
... print(ast.dump(ast.parse(code), indent=2))
...
>>> get_ast('''
... age = 21
... print(age)
... ''')
Module(
body=[
Assign(
targets=[
Name(id='age', ctx=Store())
],
value=Constant(value=21)),
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='age', ctx=Load())
],
keywords=[]
)
)
],
type_ignores=[]
)
>>>So the first statement is an Assign, and the variable age is in the "Store" context (because a new value is being stored into it), and in the second statement it is in "Load" context. Interestingly, print itself is a variable that's being loaded in this statement. Which makes sense, print is essentially a function somewhere in memory, which is accessible by us using the name print.
Let's look at a couple more. What about this?
age = age + 1The AST looks like this:
Assign(
targets=[
Name(id='age', ctx=Store())
],
value=BinOp(
left=Name(id='age', ctx=Load()),
op=Add(),
right=Constant(value=1)
)
)The age on the right is in "Load" mode and the one on the left is in "Store" mode. That's why this line of code makes sense: we are Loading the old value, adding 1 to it, and then Storing it.
This should probably help in explaining how this kind of self-assigning code really works to a newbie programmer in the future.
One more interesting example is this:
x[5] = yThe AST looks like this:
Assign(
targets=[
Subscript(
value=Name(id='x', ctx=Load()),
slice=Constant(value=5),
ctx=Store()
)
],
value=Name(id='y', ctx=Load())
)Here, x is actually in "Load" mode even though it's on the left side of the assignment. And if you think about it, it makes sense. We need to load x, and then modify one of its indices. It's not x which is being assigned to, only one index of it is being assigned. So the part of the AST that is in Store context is the Subscript, i.e. it is x[5] that's being assigned a new value.
Hopefully this explains why we explicitly need to tell each variable whether it is in a load or store context in the AST.
Now unless you're super familiar with Python, you'd think that Load and Store cover everything that the language needs, but weirdly enough there's a third possible ctx value, Del:
>>> get_ast('del x')
Module(
body=[
Delete(
targets=[Name(id='x', ctx=Del())]
)
],
type_ignores=[]
)Extras: why `del` exists
So Python is a reference-counted, garbage collected language. What that means is that there's a very clear distinction between variables and values. Values are essentially just objects floating around in memory, and variables are just names that point to the said objects in memory.
For each variable that points to a value (a.k.a "references" that value), the reference count of that value is increased. For example:
x = 'some string' # This string has a ref. count of 1
y = x # Now it has a ref. count of 2When a value in memory reaches a reference count of zero, that value is no longer used anywhere in the program. Once that happens, the value is deleted from memory (garbage collected). There's a few reasons why a value can get to zero reference counts, like a function returning:
def f():
x = 'some string' # Ref count 1
print(x)
# Now, when this function returns, `x` is deleted
# making the string's reference count zero.
f()Or, if you explicitly delete it:
x = 'some string' # Count 1
del x # Count 0. That string is gone forever.Note that re-assigning a variable is the same as deleting it and then assigning it. Which means this:
x = 'some string' # Count 1
x = 'other string' # Old string's count goes to 0.... is the same as this:
x = 'some string' # Count 1
del x # Count goes to 0.
x = 'other string'If you want more examples of this, there's a much more in-depth video by Anthony.
And just like Store, you can also Del an attribute or an index, and it behaves similarly:
>>> get_ast('del x[y]')
Module(
body=[
Delete(
targets=[
Subscript(
value=Name(id='x', ctx=Load()),
slice=Name(id='y', ctx=Load()),
ctx=Del()
)
]
)
],
type_ignores=[]
)Extras: type_ignores
We also haven't talked about the type_ignores=[] thing present at the bottom of every Module we output have seen so far.
It's a topic related to Python's type hints. More specifically, it refers to # type: ignore comments present in source code. They're not normally parsed by the AST, but you can pass a flag to the parsing step to tell it to check for these comments. Type checkers like mypy will use this to get type more information. Take a look at this:
>>> print(ast.dump(
... ast.parse('x = 5 # type: ignore', type_comments=True),
... indent=2
... ))
Module(
body=[
Assign(
targets=[
Name(id='x', ctx=Store())
],
value=Constant(value=5)
)
],
type_ignores=[
TypeIgnore(lineno=1, tag='')
]
)If you want to learn more about mypy and type checkers, I have a super long blog on that.
Walking the Syntax Trees with Visitors
So now we know that our AST represents code using nested Nodes, a structure that is called a "tree". We also know that in a tree structure, a node can have as many children nodes inside it as needed. With all that, comes the question of how does one "read" the tree.
The most obvious way would be to read it top to bottom, the way it appears in the AST dump that we've seen so many times:
>>> get_ast('''
... age = 21
... print(age)
... ''')
Module(
body=[
Assign(
targets=[
Name(id='age', ctx=Store())
],
value=Constant(value=21)),
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='age', ctx=Load())
],
keywords=[]
)
)
],
type_ignores=[]
)We have a Module, which has two nodes in its body: an Assign which has a Name and a Constant, and an Expr which has a Call with a couple Name nodes.
This way of reading from parent node to child node, in the sequence they appear, is called a pre-order traversal of the tree. And for most intents and purposes, it is what you need.
To implement this sort of traversal of an AST, Python provides you the NodeVisitor class, which you can use like this:
import ast
class MyVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(f'entering {node.__class__.__name__}')
super().generic_visit(node)
visitor = MyVisitor()
tree = ast.parse('''
age = 21
print(age)
''')
visitor.visit(tree)We'll look closer at the code inside
MyVisitorvery soon, but let's try and examine its output first.
This outputs the following:
entering Module
entering Assign
entering Name
entering Store
entering Constant
entering Expr
entering Call
entering Name
entering Load
entering Name
entering LoadTo make this output slightly more detailed, let's not just print the class name, but the entire node:
import ast
class MyVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(f'entering {ast.dump(node)}')
super().generic_visit(node)
visitor = MyVisitor()
tree = ast.parse('''
x = 5
print(x)
''')
visitor.visit(tree)There's a lot more output, but it might help to look at it:
entering Module(body=[Assign(targets=[Name(id='x', ctx=Store())], value=Constant(value=5)), Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Name(id='x', ctx=Load())], keywords=[]))], type_ignores=[])
entering Assign(targets=[Name(id='x', ctx=Store())], value=Constant(value=5))
entering Name(id='x', ctx=Store())
entering Store()
entering Constant(value=5)
entering Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Name(id='x', ctx=Load())], keywords=[]))
entering Call(func=Name(id='print', ctx=Load()), args=[Name(id='x', ctx=Load())], keywords=[])
entering Name(id='print', ctx=Load())
entering Load()
entering Name(id='x', ctx=Load())
entering Load()You might notice that the first line output is the entire Module. The second line is the Assign node that is inside the Module, and the third line is a Name node which is inside that. Interesting.
With that, let's understand what's going on. You can imagine this "visitor" moving from up to down, left to right in this tree structure:
<----Module---->
/ \
Assign Expr
/ \ |
Name('x') Constant(5) Call
| / \
Store() Name('print') Name('x')
| |
Load() Load()It starts from the Module, then for each child it visits, it visits the entirety of one of its children before going to the next child. As in, it visits the entirety of the Assign sub-tree before moving on to Expr part of the tree, and so on.
How it does this, is all hidden in our generic_visit() implementation. Let's start tweaking it to see what results we get. Here's a simpler example:
class MyVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(f'entering {node.__class__.__name__}')
super().generic_visit(node)
visitor = MyVisitor()
tree = ast.parse('x = 5')
visitor.visit(tree)entering Module
entering Assign
entering Name
entering Store
entering ConstantNow let's move the print statement to below the super call, see what happens:
class MyVisitor(ast.NodeVisitor):
def generic_visit(self, node):
super().generic_visit(node)
print(f'leaving {node.__class__.__name__}')
visitor = MyVisitor()
tree = ast.parse('x = 5')
visitor.visit(tree)leaving Store
leaving Name
leaving Constant
leaving Assign
leaving ModuleInteresting. So now the prints suddenly happen in sort-of "reverse" order. It's not actually reversed though, but now every child appears before the parent. This bottom-to-top, left-to-right traversal is called post-order traversal.
So how about if we do both prints together?
class MyVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(f'entering {node.__class__.__name__}')
super().generic_visit(node)
print(f'leaving {node.__class__.__name__}')
visitor = MyVisitor()
tree = ast.parse('x = 5')
visitor.visit(tree)entering Module
entering Assign
entering Name
entering Store
leaving Store
leaving Name
entering Constant
leaving Constant
leaving Assign
leaving ModuleIf you follow the enter and leave commands one by one, you'll see how this traversal is happening. I've added the corresponding line numbers for each node in an [enter, leave] pair in this graph, and you can follow the traversal from 1 through 10:
Module [1, 10]
|
Assign [2, 9]
/ \
Name('x') [3, 6] Constant(5) [7, 8]
|
Store() [4, 5]You can keep this in mind, that anything that comes before the
super()call is being done in pre-order, and anything that comes after thesuper()call is being done in post-order.
So let's say that for some reason I wanted to find how many statements exist inside all the for loops in my code. To do that, I'd need to do the following:
- Traverse through the code to find all
Fornodes. We're already sorted with that. - Each time we see a
Fornode, we need to start our count from zero. - We must keep counting until we see this same
Fornode again during post-order traversal. - For every node we find below the
Fornode, check if it's a statement, and increment count.
The code for that would look like this:
import ast
class ForStmtCounter(ast.NodeVisitor):
current_for_node = None
stmt_count = 0
def generic_visit(self, node):
# If we are inside a for node, count statements
if self.current_for_node is not None:
if isinstance(node, ast.stmt):
self.stmt_count += 1
# If we just found a new for node, start counting
elif isinstance(node, ast.For):
self.current_for_node = node
self.stmt_count = 0
super().generic_visit(node)
# This runs when coming back up from the children
if node is self.current_for_node:
# We're done counting this node. Print it out
print(f'For node contains {self.stmt_count} statements')
self.current_for_node = None
for_statement_counter = ForStmtCounter()
tree = ast.parse('''
for i in range(10):
print(i)
for item in items:
if item == 42:
print('Magic item found!')
break
''')
for_statement_counter.visit(tree)And this is the output:
For node contains 1 statements
For node contains 3 statementsThe power of AST manipulation
The real power of ASTs comes from the fact that you can edit an AST, and then compile and run it, to modify your source code's behaviour at runtime.
To get into all of that, let me explain a little bit about how Python runs your source code:
>>> import ast
>>> code = 'print("hello")'
>>> tree = ast.parse(code)
>>> print(ast.dump(tree, indent=2))
Module(
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Constant(value='hello')
],
keywords=[]
)
)
],
type_ignores=[]
)
>>> code_object = compile(tree, '<my ast>', 'exec')
>>> exec(code_object)
hello- The first step is to parse the source code. This actually involves two steps, converting the source code into tokens, and then converting the tokens into a valid AST. Python neatly exposes these two parts of the compilation step with the
ast.parsefunction. You can examine the AST produced in the output above. - The next step is to "compile" the given AST into a code object. Code objects are objects that contain compliled pieces of Python "bytecode", the variable names present in the bytecode, and the locations of each part in the actual source.
The
compilefunction takes in the AST, a file name (which we set to'<my ast>'in our case), and a mode, which we set to'exec', which tells compile that we want an executable code object to come out. - The third step is to run the
exec()on this code object, which runs this bytecode in the interpreter. It provides the bytecode with all the values present in the local and global scopes, and lets the code run. In our case, this makes the object print outhello.
If you want a more in-depth explanation of this, I have an entire section on it in my builtins blog.
Now since we have the AST in step 1 of this part, we can simply modify the AST, before we run the compile and execute steps, and the output of the program will be different. How cool is that!
Let's just jump into it with a few simple examples, before we do something really awesome with this.
Let's write one that changes all numbers in our code to become 42, because why not. Here's our test code:
print(13) # definitely not 42
num = 28
print(num)
def add(x, y):
return x + y
for i in [1, 2, 3]:
print(i)
output = add(num, 100)
print(output)Running this, we get:
13
28
1
2
3
128Now, if all numbers in this code were 42, our output would be:
42
42
42
42
42
84The last 84 is from 42 + 42 (instead of 28 + 100).
So, how would you do this? It's quite straightforward actually. What we do is define a NodeTransformer class. The difference between this and a NodeVisitor is that a Transformer actually returns a node on every visit, which replaces the old node:
import ast
class NumberChanger(ast.NodeTransformer):
"""Changes all number literals to 42."""
def generic_visit(self, node):
# if it isn't an int constant, do nothing with the node
if not isinstance(node, ast.Constant) or not isinstance(node.value, int):
return node
return ast.Constant(value=42)Let's run it and see our output:
$ python -i code.py
>>> code = '''
... print(13) # definitely not 42
...
... num = 28
... print(num)
...
... for i in [1, 2, 3]:
... print(i)
...
... output = add(num, 100)
... print(output)
... '''
>>> tree = ast.parse(code)
>>> modified_tree = NumberChanger().visit(tree)
>>> exec(compile(modified_tree, '<my ast>', 'exec'))And, as expected, the output is:
13
28
1
2
3
128... wait. That's not right. Something's definitely not right.
And with that, we are going to talk about something that's really important when it comes to playing around with ASTs: Sometimes, it can be quite hard to get right.
A tutorial can make any topic seem easy and obvious, but often times it misses out on the whole learning process of making mistakes, discovering new edge cases, and actually understanding how to debug some of these things.
Okay, mini-rant over. Let's try and debug this thing. To do that, the first thing that we should do is head to the docs:
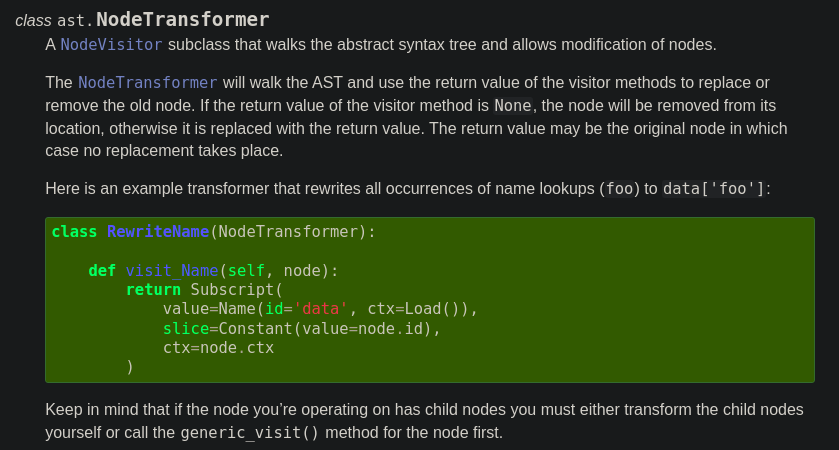
The first line below a code example says:
"Keep in mind that if the node you’re operating on has child nodes you must either transform the child nodes yourself or call the
generic_visit()method for the node first."
Ah, yes, we forgot the super() call. But why does that matter?
The super() call is what propagates the tree traversal down the tree. If you don't call that, the visit method will stop on that specific node, and never visit the node's children. So, let's fix this:
import ast
class NumberChanger(ast.NodeTransformer):
"""Changes all number literals to 42."""
def generic_visit(self, node):
super().generic_visit(node) # Added this line
# if it isn't an int constant, do nothing with the node
if not isinstance(node, ast.Constant) or not isinstance(node.value, int):
return node
return ast.Constant(value=42)Let's run it again:
$ python -i code.py
>>> code = '''
... print(13) # definitely not 42
...
... num = 28
... print(num)
...
... for i in [1, 2, 3]:
... print(i)
...
... output = add(num, 100)
... print(output)
... '''
>>> tree = ast.parse(code)
>>> modified_tree = NumberChanger().visit(tree)
>>> exec(compile(modified_tree, '<my ast>', 'exec'))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: required field "lineno" missing from exprUh oh. Another error. Welp, back to the docs.
This is what the rest of the section on NodeTransformer says:
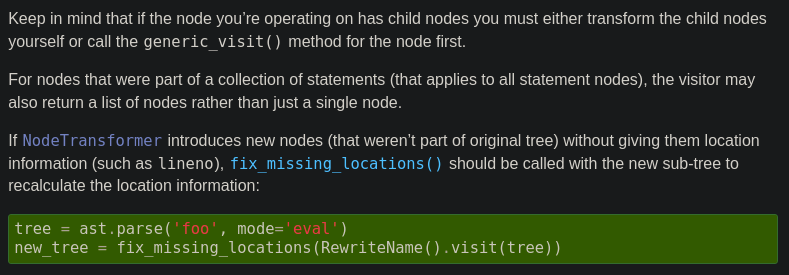
That's exactly what we need to do, run fix_missing_locations. Always read the entirety of the docs, folks. Let's run it again:
>>> modified_tree = ast.fix_missing_locations(modified_tree)
>>> exec(compile(modified_tree, '<my ast>', 'exec'))
42
42
42
42
42
84Finally! We were able to modify and run our AST 🎉
Let's go a little more in depth. This article is super long already, might as well add some more interesting stuff.
Since it's very common for AST modifications to deal with a specific kind of node, and nothing else (We've already seen a few examples where that would've been useful, such as turning every number into 42), The NodeVisitor and NodeTransformer classes both let you define Node-specific visitor methods.
You define a node-specific visitor method by defining a visit_<NodeName> method, just as visit_For to just visit for-loops. If the visitor encounters a for loop, it will first see if a visit_For is defined in the class, and run that. If there isn't, it runs generic_visit as the fallback.
Here's a somewhat wacky example, which lets you run a program that outputs to the terminal, and make it so that it outputs to a file instead. To do that, we're going to rewrite every print call, and add an attribute, file=..., which will make it print to that file instead.
Let's see what the AST looks like, for a print() call with and without a file=... attribute.
>>> get_ast('print(x)')
Module(
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='x', ctx=Load())
],
keywords=[]
)
)
],
type_ignores=[]
)
>>> get_ast('print(x, file=myfile)')
Module(
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='x', ctx=Load())
],
keywords=[
keyword(
arg='file',
value=Name(id='myfile', ctx=Load())
)
]
)
)
],
type_ignores=[]
)So we need to find every Call with the func attribute being Name(id='print'), and add a file property to the Call's keywords.
import ast
class FileWriter(ast.NodeTransformer):
def visit_Call(self, node):
super().generic_visit(node)
if isinstance(node.func, ast.Name) and node.func.id == "print":
node.keywords.append(
ast.keyword(
arg="file",
value=ast.Name(id="myfile", ctx=ast.Load()),
)
)
# Remember to return the node
return nodeTime to test this:
$ python -i code.py
>>> for i in range(1, 6):
... print('*' * i)
...
*
**
***
****
*****
>>> import ast
>>> code = '''
... for i in range(1, 6):
... print('*' * i)
... '''
>>> tree = ast.parse(code)
>>> new_tree = FileWriter().visit(tree)
>>> new_tree = ast.fix_missing_locations(new_tree)
>>> with open('output.txt', 'w') as myfile:
... exec(compile(new_tree, '<ast>', 'exec'))
...
>>> exit()
$ cat output.txt
*
**
***
****
*****If you want to, a nice exercise for checking your understanding would be to re-write every generic_visit based code we have written so far, and simplify it using visit_X methods instead.
I'd love to talk a lot more in depth about all the insane stuff you can do in Python by modifying and executing ASTs. But unfortunately there's not enough space in this blog post for that. Trust me.
If you really want to look into more examples of this, you can check out the source code of zxpy after reading this article. It is a library that essentially adds new syntax to Python strings, to seamlessly execute shell code within Python. It is mind-bending stuff though.
Let's build: A simple linter
We've learned all the key components for this, all that's left to do is to put everything together. Let's write our own linter from scratch.
Here's the idea:
- We're gonna make a
Linterclass, which holds our "lint rules". - Lint rules are the actual checks that run on the code. They comprise of 3 things:
- A rule "code" that uniquely identifies it,
- A message that explains the rule violation to the user,
- And a
Checkerclass, which is an AST visitor that checks which nodes violate this rule in the source code.
- Our linter class will register these rules, run them on a file, and print out all violations.
So let's write down our linter framework, mylint.py:
import ast
import os
from typing import NamedTuple
class Violation(NamedTuple):
"""
Every rule violation contains a node that breaks the rule,
and a message that will be shown to the user.
"""
node: ast.AST
message: str
class Checker(ast.NodeVisitor):
"""
A Checker is a Visitor that defines a lint rule, and stores all the
nodes that violate that lint rule.
"""
def __init__(self, issue_code):
self.issue_code = issue_code
self.violations = set()
class Linter:
"""Holds all list rules, and runs them against a source file."""
def __init__(self):
self.checkers = set()
@staticmethod
def print_violations(checker, file_name):
for node, message in checker.violations:
print(
f"{file_name}:{node.lineno}:{node.col_offset}: "
f"{checker.issue_code}: {message}"
)
def run(self, source_path):
"""Runs all lints on a source file."""
file_name = os.path.basename(source_path)
with open(source_path) as source_file:
source_code = source_file.read()
tree = ast.parse(source_code)
for checker in self.checkers:
checker.visit(tree)
self.print_violations(checker, file_name)Sweet. Now that we have a framework, we can start writing our own checkers. Let's start with a simple one, one that checks if a set has duplicate items:
class SetDuplicateItemChecker(Checker):
"""Checks if a set in your code has duplicate constants."""
def visit_Set(self, node):
"""Stores all the constants this set holds, and finds duplicates"""
seen_values = set()
for element in node.elts:
# We're only concerned about constant values like ints.
if not isinstance(element, ast.Constant):
continue
# if it's already in seen values, raise a lint violation.
value = element.value
if value in seen_values:
violation = Violation(
node=element,
message=f"Set contains duplicate item: {value!r}",
)
self.violations.add(violation)
else:
seen_values.add(element.value)The only thing left, is to write a main function, that takes the filenames from the commandlint, and runs the linter:
def main():
source_path = sys.argv[1]
linter = Linter()
linter.checkers.add(SetDuplicateItemChecker(issue_code="W001"))
linter.run(source_path)
if __name__ == "__main__":
main()That was a lot of code, but hopefully you were able to make sense of all of it. Alright, time to lint some files. I wrote a test.py file to test our linter:
$ cat test.py
s = {1, 2}
l = [1, 2, 3, 1, 2, 3]
def main():
for item in l:
methods = {
"GET",
"PUT",
"POST",
"DELETE",
"PUT", # This is a duplicate
}
if item in methods:
print(item)
s2 = {1, 2, 3, 1} # Has duplicatesLet's run:
$ python mylint.py test.py
test.py:11:12: W001: Set contains duplicate item: 'PUT'
test.py:16:15: W001: Set contains duplicate item: 1We've successfully written a linter!
The real fun starts though, with the really intricate lint rules that you can write. So let's write one of those. Let's try to write a checker that checks for unused variables.
Here's the idea: Every function has a local scope, where you can define new variables. These variables only exist within that function, they have to be created and used all within that function. But, if a variable is defined but isn't used in a function, that's an unused variable.
To detect unused variables, we can visit all Name nodes inside a function or class, and see if there's any in Load context. If a variable is only ever present in Store context, that means it's defined but never used. So let's do that:
class UnusedVariableInScopeChecker(Checker):
"""Checks if any variables are unused in this node's scope."""
def __init__(self, issue_code):
super().__init__(issue_code)
# unused_names is a dictionary that stores variable names, and
# whether or not they've been found in a "Load" context yet.
# If it's found to be used, its value is turned to False.
self.unused_names = {}
# name_nodes holds the first occurences of variables.
self.name_nodes = {}
def visit_Name(self, node):
"""Find all nodes that only exist in `Store` context"""
var_name = node.id
if isinstance(node.ctx, ast.Store):
# If it's a new name, save the node for later
if var_name not in self.name_nodes:
self.name_nodes[var_name] = node
# If we've never seen it before, it is unused.
if var_name not in self.unused_names:
self.unused_names[var_name] = True
else:
# It's used somewhere.
self.unused_names[var_name] = FalseThere's just one caveat: We can't just use this visitor on our entire file, as it won't find all unused variables. Here's a quick code example to demonstrate:
def func():
var = 5
var = 10
print(var)Here, we would see var being used in the global scope. Because of that, the checker won't catch the unused var inside func(), if we only run it on the entire file. We actually want to run this checker on every single function and class in the file.
So that's exactly what we are going to do. We will write a checker that runs this checker inside it. Yeah, my mind was also blown when I realised I can run visitors inside visitors. But here's the plan: For every ClassDef and FunctionDef, we will run the above checker on them to find unused local variables, and we will also run it on the Module to find globally unused variables. Sounds good?
class UnusedVariableChecker(Checker):
def check_for_unused_variables(self, node):
"""Find unused variables in the local scope of this node."""
visitor = UnusedVariableInScopeChecker(self.issue_code)
visitor.visit(node)
# Now the visitor has collected data, and we can use that data
for name, unused in visitor.unused_names.items():
if unused:
node = visitor.name_nodes[name]
self.violations.add(Violation(node, f"Unused variable: {name!r}"))
def visit_Module(self, node):
self.check_for_unused_variables(node)
super().generic_visit(node)
def visit_ClassDef(self, node):
self.check_for_unused_variables(node)
super().generic_visit(node)
def visit_FunctionDef(self, node):
self.check_for_unused_variables(node)
super().generic_visit(node)All that's left now, is to enable this checker in the main function:
def main():
source_path = sys.argv[1]
linter = Linter()
linter.checkers.add(SetDuplicateItemChecker(issue_code="W001"))
linter.checkers.add(UnusedVariableChecker(issue_code="W002"))
linter.run(source_path)I've also prepared a new test file, with some more variables:
s = {1, 2} # Unused global
l = [1, 2, 3, 1, 2, 3]
def main():
var = 5 # Unused local
for item in l:
methods = {
"GET",
"PUT",
"POST",
"DELETE",
"PUT", # Duplicate
}
if item in methods:
print(item)
s2 = {1, 2, 3, 1} # Unused, and has a duplicate
var = 7
print(var)Alright, let's run it!
$ python mylint.py test.py
test.py:1:0: W002: Unused variable: 's'
test.py:17:0: W002: Unused variable: 's2'
test.py:5:4: W002: Unused variable: 'var'
test.py:17:15: W001: Set contains duplicate item: 1
test.py:12:12: W001: Set contains duplicate item: 'PUT'It works! We did it, we've built our own linter 🥳
If you've made it all the way to this part of the post, congratulations. Even though I've tried my best, I wouldn't be surprised if people still find this article too hard to follow. But, that's just the nature of code analysis -- it's hard. It took me 6 months of working with Python's AST every single day to be able to write this blog, so if you've appreciated the work I'd love to hear about it 🙌
AST utilities
The AST module gives you a few other useful utility classes:
-
ast.literal_evalcan be used as a safer alternative toeval, asliteral_evaldoesn't access the Python environment, and can only parse literal values, like'abc'or"{'name': 'Mike', 'age': 25}". But sometimes, that's all you need to evaluate, and it's infinitely safer than usingevalfor that.>>> import ast >>> ast.literal_eval('5') 5 >>> ast.literal_eval("{'name': 'Mike', 'age': 25}") {'name': 'Mike', 'age': 25} >>> your_password = 'password123' >>> eval('"abc" + your_password') # eval can access variables outside, insecure 'abcpassword123' >>> ast.literal_eval('"abc" + your_password') # trying to use variables etc. fails ValueError: malformed node or string: <ast.Constant object at 0x7f33a7cdaa90> -
ast.unparsewas added in Python 3.9, and can take an AST node and convert it back to source code.Note that ASTs don't store all the information from a source file, so things like exact whitespace information, comments, use of single/double quotes etc. will be lost when you do this. But it still works:
>>> import ast >>> code = ''' ... def x(): ... print("Hello") # Some comment ... def y(): pass ... ''' >>> tree = ast.parse(code) >>> print(ast.unparse(tree)) def x(): print('Hello') def y(): passRe-parsing an un-parsed AST again should generate the same AST.
-
ast.walktakes in an AST node and returns a generator, that yields all of its children one by one, in no specific order.>>> import ast >>> tree = ast.parse(''' ... while True: ... x = 'hi' ... if len(x) == 2: ... break ... ''') >>> for node in ast.walk(tree): ... print('Found', node.__class__.__name__) ... Found Module Found While Found Constant Found Assign Found If Found Name Found Constant Found Compare Found Break Found Store Found Call Found Eq Found Constant Found Name Found Name Found Load Found Load
What about code formatters?
A little while ago I mentioned that ASTs don't contain certain information like whitespaces, comments, and quote styles. This is because ASTs are meant to be a representation of what the code means, not how the code looks. Anything that Python won't need to store to run the code, is stripped out.
Turns out, this is a huge problem if you want to create things like code formatters, which need to be able to produce the exact source code that was used to build the syntax trees. If you don't, everytime the code formatter runs on your file, the whole file will look completely different from how you wrote the code.
For such use cases, we need what is called a Concrete Syntax Tree, or CST. A CST is essentially just an AST which contains style information as well, such as where the newlines are, how many spaces are used for indentation, and so on.
If you need to build a code editor, formatter, or something of that sort for Python, I'll highly recommend libcst. It's the best CST library for Python that I know of.
Where can I learn more?
If you somehow still want to learn more about ASTs, then my first recommendation would be to read all of the documentation of the ast module. Furthermore, you should also check out greentreesnakes, which was the original source of most of the code examples in the official tutorial today. There's a lot of material to read there.
One of the craziest parts about the ast module is that, even with all the amazing things it lets us do, the entire source code ast.py is just 1700 lines of Python code. It's a definite must-read if you want to dive deeper into ASTs.
The linter that I wrote can be found on my github. It can be thought of as an an extremely simplified version of pylint, one of the most popular linters in Python, which also has its own AST wrapper called astroid.
And with that, you've reached the end of the article. I hope you find good use of this.